Brian's brain, on Common Lisp, take 2
While writing code for the first version of Brian's Brain some things crept into my mind, but I left them out of the article to keep it focused. The main issues are:
- Using symbols to represent cells is not very efficient since a symbol is a kind of object, which means it is a pointer, which means it takes 32 or 64 bits of storage. 2 bits would be enough in our case.
- Computer memory is linear (well, from a programmer's point of view), and 2-dimensional arrays are figments of our imagination. I mean, in the end it's still a 1-dimensional array, with some support from the programming language to make it appear as something else. Is it worth the trouble to implement the 2D world with a 1D array if the language (Common Lisp in this case) provides us with 2D arrays?
- Currently a new array is allocated for each simulation step, which is not strictly necessary. Each simulation step needs only two arrays – for current world state and the next one. Since all cells of the new state are overwritten on each step, we don't need to create a completely new array to store them – we can reuse the one from previous step.
Specialised arrays
I'll start with changing the cell representation – instead of symbols I'll use numbers. And the world is going to be a suitable array. This is also a good time to tell a bit about arrays and their types to those unfamiliar with Common Lisp.
The arrays I used for the first implementation of Brian's Brain were
of type T, which is the most generic array type possible, and it can
store any kind of objects. It is also possible to specify the type
of objects that will be stored in an array when creating it. And
Common Lisp implementation will choose the most specific type of array
that can store objects of specified type.
In my case I want to use array store numbers from 0 to 2. There is an
integer type in Common Lisp which is the type of mathematical
integer (with unlimited magnitude). It is also possible to limit the
magnitude by specifying the lower and upper limit. Here's how to
create an array that is suitable for storing integers from 0 to 2 in
Common Lisp (SBCL):
CL-USER> (make-array 7 :element-type '(integer 0 2))
#(0 0 0 0 0 0 0)
We can also check what is the exact type of the object that has been created:
CL-USER> (type-of (make-array 7 :element-type '(integer 0 2)))
(SIMPLE-ARRAY (UNSIGNED-BYTE 2) (7))
As we can see, the type of the array created is (unsigned-byte 2),
which means all non-negative integers representable by 2 bits (see the
documentation of unsigned-byte for more details). The type returned
is more general than what I have asked for, but as I said, it is up to
Common Lisp implementation to choose what type of array to create.
There is also a function that can tell what type of array will be
created given a type specifier. Let's see, again on SBCL:
CL-USER> (upgraded-array-element-type '(integer 0 2)) (UNSIGNED-BYTE 2) CL-USER> (upgraded-array-element-type '(integer 0 42)) (UNSIGNED-BYTE 7)
A different Common Lisp implementation is allowed to work differently. Here is what 32-bit Clozure CL tells us:
CL-USER> (upgraded-array-element-type '(integer 0 2))
(UNSIGNED-BYTE 8)
CL-USER> (upgraded-array-element-type '(integer 0 42))
(UNSIGNED-BYTE 8)
CL-USER> (type-of (make-array 7 :element-type '(integer 0 2)))
(SIMPLE-ARRAY (UNSIGNED-BYTE 8) (7))
As you can see, in Clozure CL 8-bit-byte is the most specific array type available for arrays of small integers. There are many places in Common Lisp specification where implementations are given freedom of implementation choices. For instance, this specific issue is described in array upgrading section.
So now we are ready to work with numbers as cell representations. 0 for dead cell, 1 for alive cell, and 2 for dying cell:
(defun make-brain (w h) (make-array (list h w) :element-type '(integer 0 2))) (defun make-initialised-brain (w h) (let ((cells (make-brain w h)) (mid (floor w 2))) (setf (aref cells 0 mid) 1) (setf (aref cells 0 (1+ mid)) 1) cells)) (defun rules (state neighbours) (case state (1 2) (2 0) (t (if (= 2 (count 1 neighbours)) 1 0))))
All other code stays as it was. Now is a good time to recall the odd graph from last time (scaled to match other graphs below):
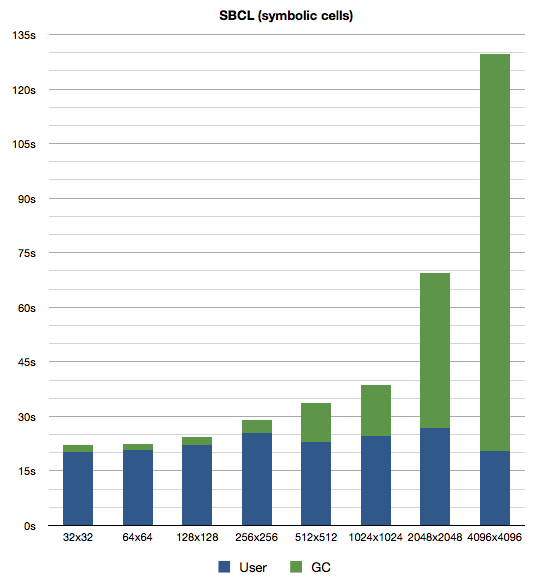
And the new version:
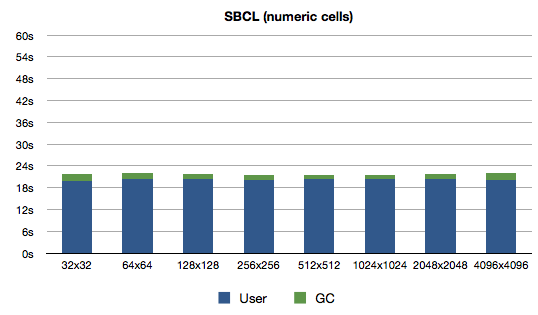
Quite a nice improvement for such a small change. I guess my theory about GCing large arrays was correct. The times for Clozure CL have also improved, not quite that dramatically though:
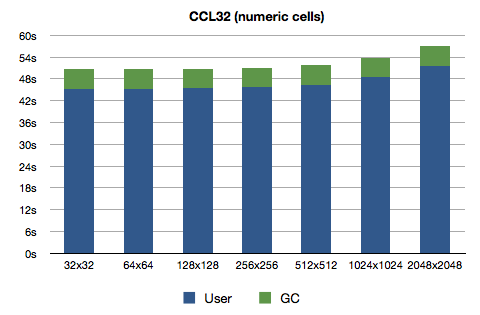
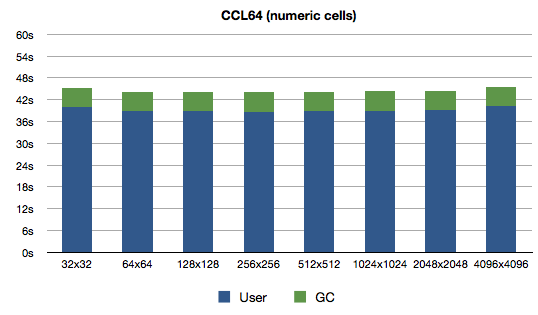
What do we learn? Lisp programmers can learn the price of some things1.
Destructive action
Next step is to avoid allocating a new array at each evolution step. I'm not expecting any serious performance gains from this because at this point each iteration is creating a single object that does not have to be traversed by GC. Let's see if I can shed some light on the believers in manual memory management lurking in the dark corners of intarwebs.
First I'll make evolve take another parameter – the array where the
next generation cells will be put into:
(defun evolve (src dst) (let* ((w (array-dimension src 1)) (h (array-dimension src 0))) (loop for j below h do (loop for i below w do (setf (aref dst j i) (funcall 'rules (aref src j i) (neighbours src i j))))) dst))
Easy, one parameter more, one line less. Now simulate will need two
brains and will alternate them at each call to evolve:
(defun simulate (steps a b) (loop repeat steps do (psetf a (evolve a b) b a) finally (return a)))
benchmark also must be updated to pass brain (of proper size) to
simulate:
(defun benchmark () (format *trace-output* "Benchmarking on ~A ~A~%" (lisp-implementation-type) (lisp-implementation-version)) ;; Warmup. (simulate 10000 (make-initialised-brain 16 16)) (loop for (w h i) in '((32 32 32768) (64 64 8192) (128 128 2048) (256 256 512) (512 512 128) (1024 1024 32) (2048 2048 8) (4096 4096 2)) do #+ccl (gc) #+sbcl (gc :full t) (let ((initial (make-initialised-brain w h)) (spare (make-brain w h))) (format *trace-output* "*** ~Dx~D ~D iteration~:P ***~%" w h i) (time (simulate i initial spare)) (finish-output *trace-output*))) (values))
Here, take a close look at the graphs now:
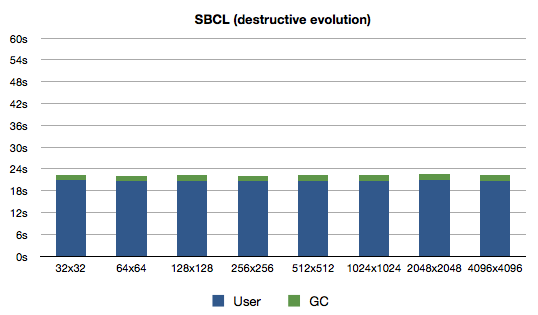
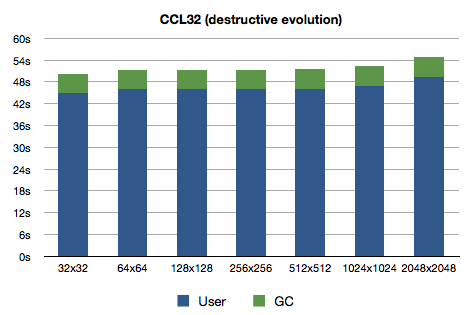
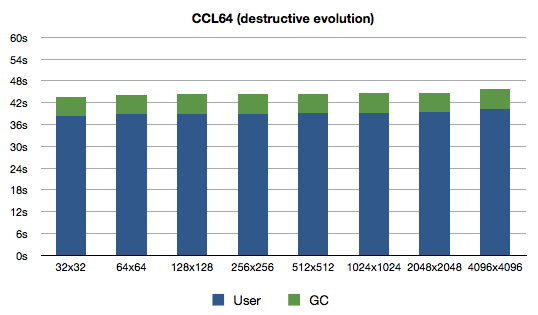
Notice anything interesting? Right, the performance has not improved noticeably. It has actually decreased slightly for SBCL and 64-bit Clozure CL. What's the lesson? Garbage Collector will make your life easier (if you don't deliberately spam it).
Dimension warp
The last exercise today will be to test whether it is worth the trouble of implementing 2-dimensional arrays on top of 1-dimensional arrays manually. This means doing the index calculations manually. I'll branch this experiment off the numerical branch.
Let's start with the easy things – creating the arrays:
(defun make-brain (w h) (make-array (* w h) :element-type '(integer 0 2)))
All that has to be changed in make-initialised-brain is to remove
the extra dimension (because we only change the first row, and first
row in our array are first w cells):
(defun make-initialised-brain (w h) (let ((cells (make-brain w h)) (mid (floor w 2))) (setf (aref cells mid) 1) (setf (aref cells (1+ mid)) 1) cells))
The main function that has to be changed is neighbours. The
function is very simple, although a bit lengthy (comparing to other
incorrect versions), but I like to keep the intent of the code close
to how I'd do things myself if I were pretending to be a computer:
(defun neighbours (cells i w h) (let ((l (length cells)) (mx (1- w)) (my (1- h))) (multiple-value-bind (y x) (truncate i w) (flet ((up (i) (if (zerop y) (- (+ i l) w) (- i w))) (dn (i) (if (= y my) (- (+ i w) l) (+ i w))) (lt (i) (if (zerop x) (1- (+ i w)) (1- i))) (rt (i) (if (= x mx) (1+ (- i w)) (1+ i)))) (let* ((u (up i)) (d (dn i)) (l (lt i)) (r (rt i)) (ul (lt u)) (ur (rt u)) (dl (lt d)) (dr (rt d))) (mapcar (lambda (i) (aref cells i)) (list ul u ur l r dl d dr)))))))
cells is the 1-dimensional array that is used to simulate the
2-dimensional array. i is the index of a cell for which the
neighbours should be calculated. And since cells is a 1-dimensional
array and does not have any information about what dimensions are
stored in it, w and h specify the dimensions of 2-dimensional
array. (If it is not clear to you why these dimensions must be
specified think about how many different 2-dimensional arrays can be
stored in 24-element 1-dimensional array).
I have written this function in a way that allows me to think about
the 1D array as a 2D array. So from i and w the x and y
coordinates are calculated. These are used to detect if the cell
under question is on the top (0) row or leftmost (0) column. For
bottom row and rightmost column I have my and mx, respectively.
Then come four local utility functions to determine an index that is
up (up), down (dn), left (lt) or right (rt) of a given cell.
The logic is the same as in the 2D array version.
Next I calculate indices for up, down, left and right cells using the above mentioned functions. The cells on diagonals are calculated relative to these. For instance, up-left cell can be obtained by going up from left cell or going left from up cell.
In the end the obtained indices are used to get cell values from
cells array. And that's all there is to it.
Now evolve also can be simplified a bit since only one dimension has
to be traversed. However, the brain dimensions must be specified
explicitly since the dimensions of the brain cannot be obtained from
the 1D array.
(defun evolve (src w h) (let* ((l (length src)) (dst (make-brain w h))) (loop for i below l do (setf (aref dst i) (funcall 'rules (aref src i) (neighbours src i w h)))) dst))
The dimensions must be dragged through simulate function, too:
(defun simulate (steps initial w h) (loop with brain = initial repeat steps do (setf brain (funcall 'evolve brain w h)) finally (return brain)))
The code gets ever uglier. Another way to solve this problem would be to create a container object (like a structure or class) to hold the cells array and the two dimensions. But that is really not the point of this exercise – I actually expect the gains from this change to be so minimal (if any!) that it is not worth the trouble at all.
OK, last change – brain dimensions must be passed to simulate:
(defun benchmark () (format *trace-output* "Benchmarking on ~A ~A~%" (lisp-implementation-type) (lisp-implementation-version)) ;; Warmup. (simulate 10000 (make-initialised-brain 16 16) 16 16) (loop for (w h i) in '((32 32 32768) (64 64 8192) (128 128 2048) (256 256 512) (512 512 128) (1024 1024 32) (2048 2048 8) (4096 4096 2)) do #+ccl (gc) #+sbcl (gc :full t) (let ((initial (make-initialised-brain w h))) (format *trace-output* "*** ~Dx~D ~D iteration~:P ***~%" w h i) (time (simulate i initial w h)) (finish-output *trace-output*))) (values))
So, let's see what do we get:
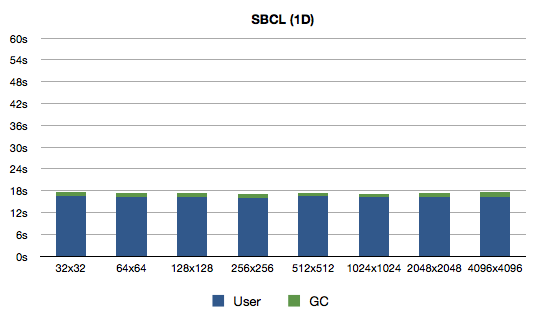
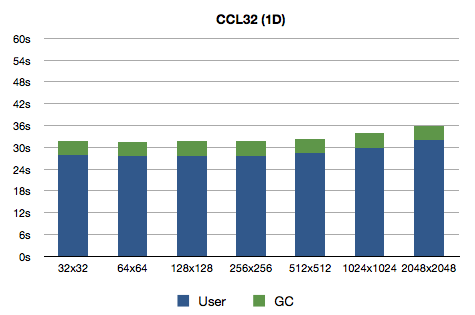
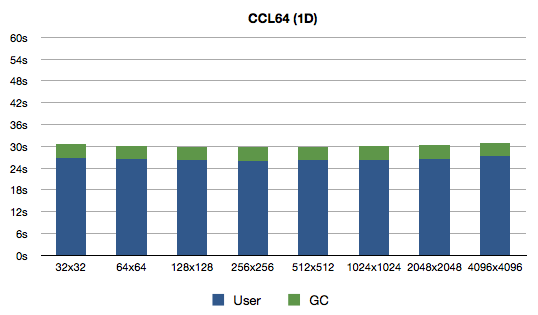
Oh man was I wrong! Why would the difference be so big? A profiler would come in handy, but before that I'd like to do another experiment because I have a feeling about the source of slowness: there are no declarations and generic array access code for 2D arrays might be more complex than for 1D arrays. Or maybe I should give profiler a shot?
Looking into future
The problem is that performance tweaking this brute-force solution seems a bit pointless. The point of these articles was to show how I would implement the Brian's Brain in Common Lisp (and do some apples-to-oranges comparisons to spice things up). A really interesting thing to try out would be to implement Hashlife, which promises an astronomic speed explosion, and see how it works with Brian's Brain. And I suspect that generating "6 octillion generations in 30 seconds" would not quite work out because Brian's Brain is a lot more chaotic (I have not noticed a single oscillator while watching my animations) – the presence of "dead" cells force a lot of movement (and expansion). I noticed quite a few spaceships, though.
I also installed Golly – a wonderful application to play with cellular automata. It has the Hashlife algorithm implemented, and it really does wonders. However it did not work out for Brian's Brain (starting with 2 live cells as I've been doing all this time) because:
- In 30 seconds it does not even get to generation 2000.
- The pattern is ever-expanding and I could not find any way to limit the world size (i.e., I think the torus-world is not implemented in Golly).
So I'd have to implement Hashlife myself. Except that I'm hesitant to hand out $30 for the original B. Gosper's paper, but might as well do it in the future (since as an extra bonus the original implementation was done on Lisp Machine).
So, I think I'll do one more iteration with the brute-force method (with profiling and declarations). And then we'll see what will happen.
Data files
Sources:
numeric.lisp
destructive.lisp
1d.lisp
Benchmarking transcripts:
bm-num-sbcl.txt
bm-num-ccl32.txt
bm-num-ccl64.txt
bm-des-sbcl.txt
bm-des-ccl32.txt
bm-des-ccl64.txt
bm-1d-sbcl.txt
bm-1d-ccl32.txt
bm-1d-ccl64.txt
Updates
2009-11-01: Please don't send me any more copies of Gosper's paper :)
Footnotes:
Alan Perlis, Epigrams in Programming, "55. A LISP programmer knows the value of everything, but the cost of nothing."