Brian's brain, on Common Lisp, take 3
This is the last installment about the straight-forward implementation of Brian's Brain in which I'm going to try to squeeze some more performance out of the brute-force implementation (you should get familiar with first and second post to get the full picture). The point of the article is not about how fast I can get it, but rather about what performance difference can be achieved using "simple" performance tweaking measures.
As any good programmer will tell you – optimizing without profiling first is a waste of time. To profile my code I will use SBCL's statistical profiler. It is called statistical because of the way it works: interrupting the running program at regular intervals and looking what code is running at that moment.
To get the idea of where the time is spent in my program I'll do a single simulation from our benchmark (with an increased iteration count to get more correct statistics):
CL-USER> (sb-sprof:with-profiling (:report :flat :loop nil)
(simulate 4096 (make-initialised-brain 128 128) 128 128))
Number of samples: 4426
Sample interval: 0.01 seconds
Total sampling time: 44.26 seconds
Number of cycles: 0
Sampled threads:
#<SB-THREAD:THREAD "initial thread" RUNNING {10029559D1}>
Self Total Cumul
Nr Count % Count % Count % Calls Function
------------------------------------------------------------------------
1 1401 31.7 1401 31.7 1401 31.7 - "foreign function sigprocmask"
2 1000 22.6 1737 39.2 2401 54.2 - NEIGHBOURS
3 552 12.5 1056 23.9 2953 66.7 - COUNT
4 200 4.5 200 4.5 3153 71.2 - SB-IMPL::OPTIMIZED-DATA-VECTOR-REF
5 179 4.0 179 4.0 3332 75.3 - SB-KERNEL:HAIRY-DATA-VECTOR-REF/CHECK-BOUNDS
6 173 3.9 173 3.9 3505 79.2 - SB-VM::GENERIC-+
7 145 3.3 247 5.6 3650 82.5 - (LAMBDA (SB-IMPL::X))
8 143 3.2 143 3.2 3793 85.7 - TRUNCATE
9 128 2.9 128 2.9 3921 88.6 - SB-KERNEL:%COERCE-CALLABLE-TO-FUN
10 116 2.6 139 3.1 4037 91.2 - LENGTH
11 80 1.8 80 1.8 4117 93.0 - EQL
12 67 1.5 2970 67.1 4184 94.5 - EVOLVE
13 51 1.2 51 1.2 4235 95.7 - (FLET LT)
14 42 0.9 42 0.9 4277 96.6 - (FLET RT)
15 41 0.9 41 0.9 4318 97.6 - SB-KERNEL:SEQUENCEP
16 30 0.7 34 0.8 4348 98.2 - NTHCDR
17 27 0.6 1076 24.3 4375 98.8 - RULES
18 22 0.5 22 0.5 4397 99.3 - (FLET #:CLEANUP-FUN-[CALL-WITH-SYSTEM-MUTEX/WITHOUT-GCING]146)
19 17 0.4 17 0.4 4414 99.7 - "foreign function mach_msg_server"
20 11 0.2 11 0.2 4425 100.0 - (FLET SB-IMPL::FAST-NTHCDR)
21 1 0.02 1 0.02 4426 100.0 - (FLET #:CLEANUP-FUN-[INVOKE-INTERRUPTION]41)
22 0 0.0 2973 67.2 4426 100.0 - SIMULATE
...
Ignoring the first entry related to sigprocmask (because that's sure
some implementation detail related to GC, profiling itself, or
something else I should not bother with) we can see our top candidates
for optimization:
neighbours– as expected, this is the function called most frequently (for every cell at every simulation iteration).count– standard Common Lisp function (called with the results ofneighboursto count the number of on cells).- Some implementation-specific functions dealing with vectors. One
of these functions contains a word "hairy" which I think means that
SBCL could use some hints. Declaring the
cellsarray type should hopefully get rid of these. Also should help with calls tolengthseen a few rows below. sb-vm::generic-+– most probably fromneighboursfunction. The name implies that the generic version of+function (addition) is used, instead of usingfixnumspecific one.eql– might be from call tocountinrulesfunction, being the default:testfunction.(flet lt)and(flet rt)– these are from withinneighbours. I'm pretty sure they are counted in one of the columns inneighboursrow.
The optimization plan now is simple1:
- Declare the type of
cellsarray. - Optimize
neighboursfunction. - Sprinkle some more declarations as needed.
The first step is easy – all I have to do is add the following
declaration to uses of cells array, which tells the compiler that
the array is one-dimensional (undefined length) and its elements are
of type (integer 0 2) (integers from 0 to 2):
(declare (type (simple-array (integer 0 2) (*)) cells))
OK, might as well make it a bit more generic (although just for the sake of example; the program is too short to make this worthwhile). Two types are introduced as "aliases" (that is, upon seeing one of these the compiler will expand them to corresponding types in the definition; a lot more complicated type declarations are possible):
(deftype cell () '(integer 0 2)) (deftype brain () '(simple-array cell (*)))
One important thing I should note here is that type declarations are optional in Common Lisp and the compiler is allowed to ignore them altogether. But they still provide a structured way to document code and all implementations I'm familiar with will use the declarations, if provided.
There are two extreme cases in type-checking:
- Everything is checked and declarations are ignored.
- Declarations are trusted and no type-checking is done.
In Common Lisp there is a way to instruct the compiler how to operate:
generate safe (but due to checking usually relatively slow) or unsafe
(probably fast due to the absence of checks) code. There are two
settings (optimization qualities) to directlyl control this
behavior: speed and safety. These settings can take values from
0 to 3 (zero being the "unimportant" value, 3 being "very
important"). optimize declaration identifier is used to specify
these qualities, like this:
(declare (optimize (speed 3) (safety 1)))
Specifying that speed is very important will also make some compilers (including SBCL) to be very chatty about why it cannot optimize particular parts of the code. Other implementations have specific declarations to make the compiler output optimization such notes.
Since I'll be experimenting with different optimization settings I'm going to specify them once for the whole file. It can be done with the following form at the beggining of the file:
(declaim (optimize (speed 3) (safety 1)))
Such optimization declarations can also be added on a per-function basis (or even for a specific form within a function), and is actually what is being done in day-to-day programming to optimize only the speed-critical sections of code.
And by the way – never, never ever run code with safety 0 (unless
you know what you are doing, which practically is never). But since
this is a toy program anyway, might as well try doing it to see what
performance impact does it have.
Here are the neighbours and evolve functions with added array
declarations:
(defun neighbours (cells i w h) (declare (type brain cells)) (let ((l (length cells)) (mx (1- w)) (my (1- h))) (multiple-value-bind (y x) (truncate i w) (flet ((up (i) (if (zerop y) (- (+ i l) w) (- i w))) (dn (i) (if (= y my) (- (+ i w) l) (+ i w))) (lt (i) (if (zerop x) (1- (+ i w)) (1- i))) (rt (i) (if (= x mx) (1+ (- i w)) (1+ i)))) (let* ((u (up i)) (d (dn i)) (l (lt i)) (r (rt i)) (ul (lt u)) (ur (rt u)) (dl (lt d)) (dr (rt d))) (mapcar (lambda (i) (aref cells i)) (list ul u ur l r dl d dr))))))) (defun evolve (src w h) (declare (type brain src)) (let* ((l (length src)) (dst (make-brain w h))) (declare (type brain dst)) (loop for i below l do (setf (aref dst i) (rules (aref src i) (neighbours src i w h)))) dst))
Compiling these produces a lot of complaints from the compiler. Some
of the notes from the neighbours function look like this:
; in: DEFUN NEIGHBOURS ; (ZEROP X) ; ==> ; (= X 0) ; ; note: unable to ; open-code FLOAT to RATIONAL comparison ; due to type uncertainty: ; The first argument is a REAL, not a FLOAT. ; ; note: unable to open code because: The operands might not be the same type. ; (+ I W) ; ; note: unable to ; optimize ; due to type uncertainty: ; The first argument is a REAL, not a RATIONAL. ; The second argument is a NUMBER, not a FLOAT. ; ; note: unable to ; optimize ; due to type uncertainty: ; The first argument is a REAL, not a FLOAT. ; The second argument is a NUMBER, not a RATIONAL. ; ; note: unable to ; optimize ; due to type uncertainty: ; The first argument is a REAL, not a SINGLE-FLOAT. ; The second argument is a NUMBER, not a DOUBLE-FLOAT. ; ; note: unable to ; optimize ; due to type uncertainty: ; The first argument is a REAL, not a DOUBLE-FLOAT. ; The second argument is a NUMBER, not a SINGLE-FLOAT. ...
Profiling the code now shows that I've got rid of the two vector-ref
functions. But there is still a bit of work to do on neighbours
function with all the noise compiler generates. First I'll declare
the types of parameters (and show only the relevant forms here):
(deftype array-index () `(integer 0 ,array-dimension-limit)) (declare (type brain cells) (type array-index i) (type fixnum w h))
A note on the array-index type: the actual integer range depends on
the value of array-dimension-limit, which is implementation
dependent (but usually is between 2^24 and most-positive-fixnum).
Now compiling neighbours function emits quite a short list of
compiler notes:
; in: DEFUN NEIGHBOURS ; (LIST UL U UR L R DL D DR) ; ; note: doing signed word to integer coercion (cost 20) ; ; note: doing signed word to integer coercion (cost 20) ; (FLET ((UP (I) ; (IF (ZEROP Y) ; (- # W) ; (- I W))) ; (DN (I) ; (IF (= Y MY) ; (- # L) ; (+ I W))) ; (LT (I) ; (IF (ZEROP X) ; (1- #) ; (1- I))) ; (RT (I) ; (IF (= X MX) ; (1+ #) ; (1+ I)))) ; (LET* ((U (UP I)) ; (D (DN I)) ; (L (LT I)) ; (R (RT I)) ; (UL (LT U)) ; (UR (RT U)) ; (DL (LT D)) ; (DR (RT D))) ; (MAPCAR (LAMBDA (I) (AREF CELLS I)) (LIST UL U UR L R DL D DR)))) ; ; note: doing signed word to integer coercion (cost 20) to "<return value>" ; ; note: doing signed word to integer coercion (cost 20) to "<return value>" ; ; compilation unit finished ; printed 4 notes
The two offending forms are flet and list. One solution now would
be to maybe declare types of all the eight cells in let* form. But
is there anything about this code that bothers you? You see, lists in
Common Lisp can hold any kind of values, and making a list takes time
and memory. And this code actually creates two lists (one with the
cell indices, and the one created by mapcar function). So telling
the compiler that the things that are stuffed into those lists are in
fact numbers does not make much sense (or performance difference)
because the lists are still being created and traversed.
So, in the name of optimization I'll go on and do what has to be done: make a single array for neighbours calculation and update it on each call. Here's the ugly-but-supposedly-fast version:
(deftype neighbours () '(simple-array cell (8))) (defun neighbours (cells i w h) (declare (type brain cells) (type array-index i) (type fixnum w h)) (let ((result (the neighbours (load-time-value (make-array 8 :element-type 'cell)))) (l (length cells)) (mx (1- w)) (my (1- h))) (multiple-value-bind (y x) (truncate i w) (flet ((up (i) (if (zerop y) (- (+ i l) w) (- i w))) (dn (i) (if (= y my) (- (+ i w) l) (+ i w))) (lt (i) (if (zerop x) (1- (+ i w)) (1- i))) (rt (i) (if (= x mx) (1+ (- i w)) (1+ i)))) (let* ((u (up i)) (d (dn i)) (l (lt i)) (r (rt i)) (ul (lt u)) (ur (rt u)) (dl (lt d)) (dr (rt d))) (setf (aref result 0) (aref cells ul) (aref result 1) (aref cells u) (aref result 2) (aref cells ur) (aref result 3) (aref cells l) (aref result 4) (aref cells r) (aref result 5) (aref cells dl) (aref result 6) (aref cells d) (aref result 7) (aref cells dr)) result)))))
First I define a new type that describes the neighbours array (known
to be 8 elements long at compile time). In the function itself a new
binding is introduced: result. There are two interesting things
about this binding:
- The value is created only once – when the code is loaded (in this case the behaviour is similar to static variables in C and some other languages).
- The type of array is declared (using
theform) because the value is only known at load time (as opposed to compile time). Theoretically I'd expect the compiler to figure this out by itself, but generally any code can be given toload-time-valueso the compiler apparently is not even trying to figure anything out.
So there, compiling neighbours function now gives no warnings and is
as ugly as if it was written in C. And since this function now
returns an array, this information can now be added to rules
function:
(defun rules (state neighbours) (declare (type cell state) (type neighbours neighbours)) (case state (1 2) (2 0) (t (if (= 2 (count 1 neighbours)) 1 0))))
Benchmarking now gives numbers around 11 seconds for each simulation run (i.e., the code runs almost two times faster than before). The top of the profiler output now looks like this:
Self Total Cumul
Nr Count % Count % Count % Calls Function
------------------------------------------------------------------------
1 466 24.7 527 27.9 466 24.7 - NEIGHBOURS
2 376 19.9 1152 61.0 842 44.6 - COUNT
3 194 10.3 194 10.3 1036 54.8 - SB-IMPL::OPTIMIZED-DATA-VECTOR-REF
4 141 7.5 238 12.6 1177 62.3 - (LAMBDA (SB-IMPL::X))
5 136 7.2 136 7.2 1313 69.5 - SB-KERNEL:HAIRY-DATA-VECTOR-REF/CHECK-BOUNDS
6 127 6.7 127 6.7 1440 76.2 - SB-KERNEL:%COERCE-CALLABLE-TO-FUN
7 110 5.8 118 6.2 1550 82.1 - EQL
8 86 4.6 86 4.6 1636 86.6 - "foreign function sigprocmask"
9 84 4.4 1800 95.3 1720 91.1 - EVOLVE
...
A few notable things:
- I think I'm starting to understand the second column2. That
would explain why
evolvehas 95% and other entries less. If so, thencounttakes about twice the time ofneighbours. - The
vector-reffriends are back! Sinceneighboursonly sets array values, it sure looks likecounthas dragged these into the picture.
Anyway, I have not done much lisp code profiling (and performance tuning for that matter) so I'll do a little experiment here: write my own function to count live neighbour count:
(defun rules (state neighbours) (declare (type cell state) (type neighbours neighbours)) (case state (1 2) (2 0) (t (if (= 2 (loop for x across neighbours counting (= 1 x))) 1 0))))
There is one compiler note for this loop – the count accumulation variable is checked for fixnum overflow. I'll leave it at that, wrap things up and call this my final version.
Here are the timings (with safety optimization setting of 1 and
0):
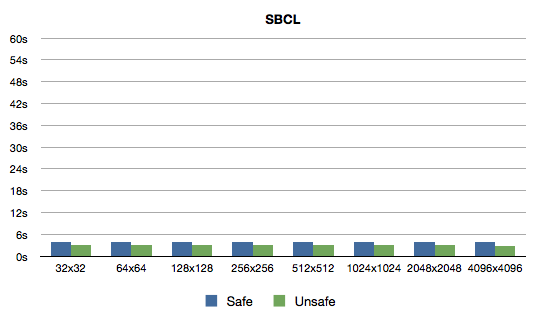
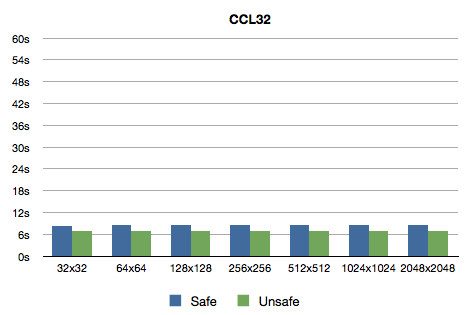
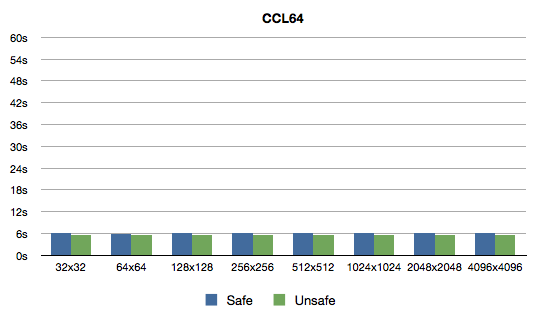
To be honest, I did not expect getting rid of count to make such a
big difference. I may only hope that this example will let
implementation developers make the compiler better!
The detailed timings can be seen in transcripts (below), but generally they are:
- 3.9s / 3s for SBCL.
- 8.5s / 6.9s for Clozure CL (32-bit).
- 6s / 5.5s for Clozure CL (64-bit).
I'm pretty sure it is possible to squeeze out some more performance out of this. I actually think that this kind of low-level optimisation is an art in itself, and I'm not very good at it. That is why I will leave this topic for now. But readers are welcome to contribute using comments or better yet – writing about it in their own blogs.
Data files
Footnotes:
A comment from pkhuong on #lisp IRC channel on approaching optimization (after reading a draft version of this article):
"Only NEIGHBOURS shows up fairly high in the list. However, before
working on it directly, I'd attack what I consider noise: COUNT,
TRUNCATE, LENGTH and EQL shouldn't be called out of line.
*-DATA-VECTOR-REF and GENERIC-+ shouldn't have to be called
either. Inserting type declarations and asking for speed optimization
where appropriate in order to eliminate these entries should be the
first step. As it is, the profile is mostly telling you that you're
doing it wrong if you really want execution speed.
Only then, with the noise eliminated, would it be time to work on the program itself, from a new profile (with the declarations and with speed optimization where needed) that may be radically different from the one above."
Another comment from pkhuong, this time about the columns in profiler output (confirming my understanding of the "total" column):
"Count" columns count samples, "%" % of time (samples). Self is the amount/% of samples with the function at the right at the top of the call stack (directly executing), total is the amount/% of time with the function somewhere on the call stack (up to a certain depth). Cumul is the sum of Self values; I find it helpful to guesstimate where the repartition of self times tapers off into a long tail.
The cycle output (not shown here nor in the blog post) is extremely useful if you know that a lot of time is spent in a function, either directly or in total, but now what the callers or the callees are. You'll be able to find the function you're looking for, the most common (in terms of sample) callers and callee. With that information, you could decide how to make a certain callee faster (or special-case it for the slow function), change the way the function is used in the slow callers, special-case the function for the slow callers, etc. The cycle output is somewhat harder to read, but the format is the same as that by gprof, so you can look around for more resources.